As enterprise supply chains and consumer demand chains have beome globalized, they continue to inefficiently share information “one-up/one-down”. Profound "bullwhip effects" in the chains cause managers to scramble with inventory shortages and consumers attempting to understand product recalls, especially food safety recalls. Add to this the increasing usage of personal mobile devices by managers and consumers seeking real-time information about products, materials and ingredient sources. The popularity of mobile devices with consumers is inexorably tugging at enterprise IT departments to shifting to apps and services. But both consumer and enterprise data is a proprietary asset that must be selectively shared to be efficiently shared.
About Steve Holcombe
Unless otherwise noted, all content on this company blog site is authored by Steve Holcombe as President & CEO of Pardalis, Inc. More profile information:
Follow @WholeChainCom™ at each of its online locations:
The following is an excerpt from an article published on September 15, 2008 in the Bits section of the New York Times:
The Web may seem ubiquitous to most of us, but its creator, Sir Tim
Berners-Lee, keeps seeing its limitations. And he keeps trying to do
something about those limitations, and make sure the Web is as open and
widely accessible as possible ....
Sir Tim is now taking another step to try to extend the Web’s reach, with the establishment of the World Wide Web Foundation.
Starting with a $5 million seed grant from the Knight Foundation, the
new Web philanthropy will begin operations next year, and is seeking
donations and volunteers. Its goal is to develop technology, tools and
expertise to help bring the Web to the 80 percent of the world’s
population that is not online. Market incentives alone, Sir Tim
suggests, will not do the job.
The term sponsored top-level domain is derived from the fact that these domains are based on theme concepts proposed by private agencies or organizations that establish and enforce rules restricting the eligibility of registrants to use the TLD.
The .Tel is a text-based naming and navigation sTLD that addresses the unique needs of the fixed-line and wireless Internet-Communications namespace. This namespace covers any form of intercommunications activity (voice, combined voice/data, or messaging) between individuals and/or businesses, which is dependent, in part or whole, on the Internet as the means of transport .... Digits are to be restricted to maintain the integrity of a letters/words based top-level domain and to avoid interference with established or future national and international telephone numbering plans .... This new sTLD will be ... a vehicle that will allow and encourage individuals and corporations to manage a universal identity in this namespace.
Telnic's raison d'etre is to provide a universal communication identifier. From application filed with ICANN:
End users are finding it increasingly difficult to remember and manage their own and other people's communication identifiers, including:
home telephone numbers
mobile telephone numbers
home fax numbers
personal email addresses
pager numbers
work telephone numbers
work telephone extension numbers
work email addresses
work fax numbers
instant messaging addresses
and other contact information
Hence, there is a need for a universal text based communication identifier under which the end user can store all their contact information.
How would .Tel be used by individuals? The following excerpt is also from the ICANN application, or you can just watch the nifty promotional movie clip, .Tel for Individuals (3m 23s).
Individuals could use their name as a personal "brand" or a universal identity accessible from any Internet-enabled communications device to publish their contact information or other personal data. For example, Adam Smith could develop a personal mini-website that provides general information about himself including his contact information, such as phone numbers, and email addresses. Adam would be able to update and manage this data at will, and Adam's friends, when trying to reach him, could simply check adamsmith.tel to find his most current contact information and connect the call or send a text message.
How would .Tel be used by businesses? Again, the following excerpt is also from the ICANN application, or you can just watch the equally jazzy promotional movie clip, .Tel for Businesses (4m 10s).
The business market has different needs than the individual market. Businesses are primarily concerned with customer acquisition and retention, ease of client communication, and efficiency of customer management. The .Tel domain has been conceived to meet each of these needs fully. Hertz, for example, could purchase hertz.tel and design a simple and clear navigational system for customers accessing the company via Internet-enabled communications devices. Hertz could segment the customer by geographic location and department and then route the customer to the appropriate call center, which enhances the customer experience and provides the most efficient and cost effective solution for Hertz.
There's another promotional movie clip posted by Telnic entitled How Do I protect My Data (1m 42s) that I found worth viewing, too. Actually, all of the several promotional movie clips at Telnic are entertaining, jazzy and informative.
The intellectual property behind .Tel is found in Communication System (US Pending Patent 20080133471) which was filed under PCT procedures by inventors John Burgess et al. in Great Britain on 1 April 2003, and in the U.S. on 1 April 2004. It is represented as being assigned to Telnic Limited. The following is a key drawing and a related excerpt from the pending patent.
[Original image modified for size and/or readability]FIG. 1 shows a schematic depiction of a system 100 according to the present invention. The system 100 comprises a user 10, a registered user 20, a registrar 30, a registry 40, a search engine 50, a name service provider (NSP) 60, a name navigation service provider (NNSP) 70, an NSP database 80 and an NNSP database 90. It will be readily appreciated that the system will operate with a plurality of both users 10 and registered users 20 but for the sake of simplicity the following discussion will be limited to a single user and registered user. The system enables a user 10, which comprises a mobile communications device (such as a mobile telephone, or wireless-enabled PDA or similar device) to obtain details regarding a registered user that has been registered with the system. Such details may comprise contact data (telephone number(s), fax number, email and/or instant messaging address, etc.) data related to content (internet address(es) for accessing or downloading multimedia resources, e-commerce or m-commerce sites, etc.). It will be understood that many different types of data may be provided. The system has a number of similarities with the existing domain name server (DNS) system. A DNS will receive a request containing an alphanumeric address and will return the IP address associated with that alphanumeric address to a client application so that a communication session may be initiated, using, for example, the ftp or http protocols. In the present invention, a database query will be run in response to a request from a client application (this is similar to a DNS look-up) and an address is returned to the client application which can be used to access the desired data. This similarity enables DNS infrastructure to be used in the implementation of the present invention.
What Telnic is doing is highly innovative from a marketing standpoint. Especially when you consider the hoops they have no doubt had to jump through in getting approval from the bureaucratic body of personalities, standards and procedures that is ICANN. I applaud them for hanging in there and bringing this service to the marketplace.
But it's little difficult to understand how Telnic's patent is innovative from the standpoint of its intellectual property (IP). The strength of what Telnic is doing is strongly tied to mimicking the DNS system, which, again, no doubt served Telnic well in receiving approval from ICANN. Moreover, in the excerpt above the inventors admit that "[t]he system has a number of similarities with the existing domain name server (DNS) system." Further evidence of this lack of IP innovativeness may be surmised from the status of Telnic's EU patent application which was withdrawn in 2007 because "[the] reply to [an] examination report [was] not received in time". That commonly means that the applicant didn't think it was worth pursuing - for whatever reason - and so abandoned the application. See the history to Communication System (Publication No. EP1609292).
To place all of the above in a broader perspective, while Telnic has taken the text-based, DNS approach to a virtual calling card system, Microsoft has taken a perhaps more object-oriented approach outside of ICANN's DNS jurisdiction for achieving a similar end with its "server-based card exchange". You can see this in comparing Telnic's IP with the summary of Microsoft's IP that I previously blogged in US Patent 7,149,977: Virtual calling card system and method. Wouldn't a mashup between the two (i.e., a web application hybrid) be interesting to see?
Update on Thursday, September 11, 2008 at 3:56PM by
Steve Holcombe
The following received from Justin Hayward, Communications Director for Telnic Limited, after reviewing the foregoing entry:
From: "Justin Hayward" <[address removed> Sent: Thursday, September 11, 2008 3:00 PM To: [addresses removed] Subject: Re: .Tel: Telnic's DNS Virtual Calling Card System
Steve,
Many thanks for your interest and kind words about .tel.
Regards,
Justin
If you have a minute, Justin has an interesting blog, Retrospective Futureologist, with updates on the launch of .Tel.
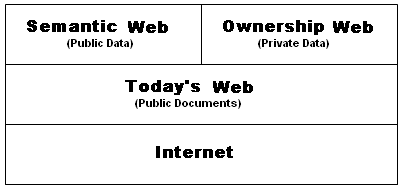
What’s right about the Semantic Web is that its most highly funded
visionaries have envisioned beyond a Web of documents to a ‘Data Web’.
Here's an example: a Web of scalably integrated data employing
object registries envisioned by Metaweb Technologies’ Danny Hillis and manifested in Freebase Parallax™, a competitive platform and application to both Google and Wikipedia.
AristotleMetaweb Technologies
is a San Francisco start-up developing and patenting
technology for a semantic ‘Knowledge Web’ marketed as Freebase Parallax.
Philosophically, Freebase Parallax is a substitute for a great tutor, like
Aristotle was for Alexander. Using Freebase Parallax users do not modify
existing web documents but instead annotate them. The annotations of Amazon.com
are the closest example but Freebase Parallax further links the annotations so
that the documents are more understandable and more findable. Annotations are also modifiable by their authors as better information becomes available to them.
Metaweb characterizes its service as an open, collaboratively-edited
database (like Wikipedia, the free encyclopedia) of cross-linked data
but, as you will see in the video below, it is really very much a next generation competitor to both Google and Wikipedia.
The Intellectual Property Behind Freebase Parallax
Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).
Freebase Parallax Incarnate
In the following video let's look at how this intellectual property for Knowledge Web is actually being engineered and applied by Metaweb Technologies in the form of Freebase Parallax.
You can hear it in the video. What Hillis and Metaweb Technologies well recognize is that as Freebase Parallax strives to become
the premier knowledge source for the Web, it will need access to new,
blue oceans of data. It
must find a gateway into the closely-held, confidential and classified
information that people consider to be their identity, that
participants to complex supply chains consider to be confidential, and
that governments classify as secret. That means that data ownership must be entered into the equation for the success of Freebase Parallax and the emerging Semantic Web in general.
Not
that Hillis hasn't thought about data ownership. He has. You can see it
in an interview conducted by his patent attorney and filed on December
21, 2001 in the provisional USPTO Patent Application 60/343,273:
Danny
Hillis: "Here's another idea that's super simple. I've never seen it
done. Maybe it's too simple. Let's go back to the terrorist version [of
Knowledge Web]. There's a particular problem in the terrorist version
that the information is, of course, highly classified .... Different
people have some different needs to know about it and so on. What would
be nice is if you ... asked for a piece of information. That you [want
access to an] annotation that you know exists .... Let's say I've got a
summary [of the annotation] that said, 'Osama bin Laden is traveling
to Italy.' I'd like to know how do you know that. That's classified.
Maybe I really have legitimate reasons for that. So what I'd like to
do, is if I follow a link that I know exists to a classified thing, I'd
like the same system that does that to automatically help me with the
process of getting the clearance to access that material." [emphasis added]
What Hillis was tapping into just a few months after 9/11 is just as relevant to today's information sharing needs.
But
bouncing around ideas about how we need data ownership is not the same
as developing methods or designs to solve it. What Hillis
non-provisionally filed, subsequent to his provisional application, was
the Knowledge Web application. Because of its emphasis
upon the statistical reliability of annotations, Knowledge web's IP is tailored made for the Semantic Web. But it is not designed for data ownership.
The Ownership Web
For the Semantic Web to reach its full potential, it
must have access to more than just publicly available data sources. Only with the empowerment of
technological data ownership in the hands of people, businesses, and
governments will the Semantic Web make contact with a horizon of new,
‘blue ocean’ data.
Conceptually, the Ownership Web would be
separate from the Semantic Web, though semantically connected as layer
of distributed, enterprise-class web platforms residing in the Cloud.
The
Ownership Web would contain diverse registries of uniquely identified
data elements for the direct authoring, and further registration, of
uniquely identified data objects. Using these platforms people,
businesses and governments would directly host the authoring, publication, sharing, control and tracking of the movement of their data objects.
The
technological construct best suited for the dynamic of networked
efficiency, scalability, granularity and trustworthy ownership is the
data object in the form of an immutable, granularly identified,
‘informational’ object.
A marketing construct well
suited to relying upon the trustworthiness of immutable, informational
objects would be the 'data bank'.
Data Banking
Traditional monetary banks meet the expectations of real people and real businesses in the real world.
People are comfortable and familiar with monetary banks. That’s a good thing because without people willingly depositing their money into banks, there would be no banking system as we know it.
By comparison, we live in a world that is at once awash in on-demand
information courtesy of the Internet, and at the same time the Internet
is strangely impotent when it comes to information ownership.
In
many respects the Internet is like the Wild West because there is no
information web similar to our monetary banking system. No similar
integrated system exists for precisely and efficiently delivering our
medical records to a new physician, or for providing access to a health
history of the specific animal slaughtered for that purchased steak.
Nothing out there compares with how the banking system facilitates
gasoline purchases.
If an analogy to the Wild West is apropos,
then it is interesting to reflect upon the history of a bank like Wells
Fargo, formed in 1852 in response to the California gold rush. Wells
Fargo wasn’t just a monetary bank, it was also an express delivery
company of its time for transporting gold, mail and valuables across
the Wild West. While we are now accustomed to next morning, overnight
delivery between the coasts, Wells Fargo captured the imagination of
the nation by connecting San Francisco and the East coast with its Pony
Express.As further described in Banking on Granular Information Ownership, today’s Web needs data banks that do for the on-going gold rush on information what Wells Fargo did for the Forty-niners.
Banks
meet the expectations of their customers by providing them with
security, yes, but also credibility, compensation, control,
convenience, integration and verification. It is the dynamic,
transactional combination of these that instills in customers the
confidence that they continue to own their money even while it is in
the hands of a third-party bank.
A data bank must do no less.
Ownership Web: What's Philosophically Needed
Where exactly is the sweet spot of data ownership?
In
truth, it will probably vary depending upon what kind of data bank we
are talking about. Data ownership will be one thing for personal health
records, another for product supply chains, and yet another for
government classified information. And that's just for starters because
there will no doubt be niches within niches, each with their own
interpretation of data ownership. But the philosophical essence of the
Ownership Web that will cut across all of these data banks will be this:
That information must be treated either or both as a tangible, commercial product or banked, traceable money.
The
trustworthiness of information is crucial. Users will not be drawn to
data banks if the information they author, store, publish and access
can be modified. That means that even the authors themselves must be
proscribed from modifying their information once registered with the
data bank. Their information must take on the immutable characteristic
of tangible, traceable property. While the Semantic Web is about the
statistical reliability of data, the Ownership Web is about the
reliability of data, period.
Ownership Web: What's Technologically Needed
What
is technologically required is a flexible, integrated architectural
framework for information object authoring and distribution. One that
easily adjusts to the definition of data ownership as it is variously
defined by the data banks serving each social network, information
supply chain, and product supply chain. Users will interface with one
or more ‘data banks’ employing this architectural framework. But the
lowest common denominator will be the trusted, immutable informational objects
that are authored and, where the definition of data ownership permits,
controllable and traceable by each data owner one-step, two-steps,
three-steps, etc. after the initial share.
Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems.
Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.).
The Beginning of the Ownership Web
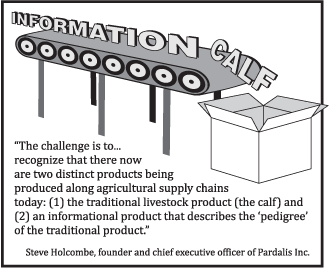
Common Point Authoring is going live this fall in the form of a data bank for cattle producers in the upper plains. Why the livestock industry? Because well-followed commentators like Dr. Kris Ringwall, Director of the Dickinson Research Extension Center for North Dakota State University, recognize that there are now two distinct products being produced along our nation's complex agricultural supply chains: (1) a traditional product, and (2) an informational product describing the pedigree of the traditional product.
"The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect.
This
is ironic because most, if not all, beef producers pride themselves on
their understanding of the skills needed to master the production of
beef. Today, there is another player simply called “data.”
The
information associated with individual cattle is critical. Producers
need to understand how livestock production is viewed ....
That
distinction is not being made and the ramifications are lost revenue in
the actual value of the calf and lost future opportunity. This is
critical for the future of the beef business ...."
Ownership Web: Where It Will Begin
The Ownership Web will begin along complex product and service supply chains where information must be trustworthy, period. Statistical reliability is not enough. And, as I mentioned above, the Ownership Web will begin this fall along an agricultural supply chain which is among the most challenging of supply
chains when it comes to information ownership. Stay tuned as the planks of the
Ownership Web are nailed into place, one by one.
As reported on August 26, 2008 by Health Content Advisors, a division of InfoCommerce Group:
Earlier this year, Steve Case used the phrase “not for the faint of heart” to describe the environment for producers of online consumer health sites. By now, most readers of this blog have heard that Revolution Health is on the block. Also, we learned last week that Xoova, a shining star among health 2.0 companies just a year ago, has quietly shut down.
These events point to a more widespread shakeout in online consumer
health sites. We’re not predicting a collapse in online consumer
healthcare resources; the long-term outlook is still very positive.
However, some companies in the most crowded, undifferentiated and
geographically dispersed segments (e.g., sites for rating
practitioners, general health and wellness sites, and social media
sites where patients share experiences) will fail and some will
consolidate. It’s a fairly predictable outcome as this hot new market
matures ....
The following is an excerpt from a New York Time's article by Claire Cain Miller:
Judy Estrin, who has built several Silicon Valley companies and was
the chief technology officer of Cisco Systems, says Silicon Valley is
in trouble. In a new book,
Closing the Innovation Gap, which will be in bookstores Tuesday, she
writes that the valley’s problems are symptomatic of a crisis in
innovation facing the country as a whole.
In an interview in her Menlo Park office Thursday, Ms. Estrin said
that the United States is stifling innovation by failing to take risks
in sectors from academia to government to venture capital. "I’m not
generally an alarmist, but I am really, really concerned about this
country," she said ....
Ms. Estrin traces Silicon Valley’s troubles to the tech boom. She said
that’s when entrepreneurs and venture capitalists started focusing more
on starting companies to turn around and sell them and less on building
successful companies for the long term ....

 Steve Holcombe
Steve Holcombe;)