
Freebase Parallax and the Ownership Web
What's Right About the Semantic Web
What’s right about the Semantic Web is that its most highly funded
visionaries have envisioned beyond a Web of documents to a ‘Data Web’.
Here's an example: a Web of scalably integrated data employing
object registries envisioned by Metaweb Technologies’ Danny Hillis and manifested in Freebase Parallax™, a competitive platform and application to both Google and Wikipedia.

AristotleMetaweb Technologies
is a San Francisco start-up developing and patenting
technology for a semantic ‘Knowledge Web’ marketed as Freebase Parallax.
Philosophically, Freebase Parallax is a substitute for a great tutor, like
Aristotle was for Alexander. Using Freebase Parallax users do not modify
existing web documents but instead annotate them. The annotations of Amazon.com
are the closest example but Freebase Parallax further links the annotations so
that the documents are more understandable and more findable. Annotations are also modifiable by their authors as better information becomes available to them.
Metaweb characterizes its service as an open, collaboratively-edited
database (like Wikipedia, the free encyclopedia) of cross-linked data
but, as you will see in the video below, it is really very much a next generation competitor to both Google and Wikipedia.
 Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).
Click
on the thumbnail image to the left and you will see in more detail what
Hillis envisions. That is, a database represented as a labeled graph,
where data objects are connected by labeled links to each other and to
concept nodes. For example, a concept node for a particular category
contains two subcategories that are linked via labeled links
"belongs-to" and "related-to" with text and picture. An entity
comprises another concept that is linked via labeled links "refers-to,"
"picture-of," "associated-with," and "describes" with Web page,
picture, audio clip, and data. For further information about this intellectual property - entitled Knowledge Web - see the blogged
entry US Patent App 20050086188: Knowledge Web (Hillis, Daniel W. et al).
Freebase Parallax Incarnate
In the following video let's look at how this intellectual property for Knowledge Web is actually being engineered and applied by Metaweb Technologies in the form of Freebase Parallax.
Freebase Parallax: A new way to browse and explore data from David Huynh on Vimeo.
The Semantic Web's Achilles Heel
You can hear it in the video. What Hillis and Metaweb Technologies well recognize is that as Freebase Parallax strives to become the premier knowledge source for the Web, it will need access to new, blue oceans of data. It must find a gateway into the closely-held, confidential and classified information that people consider to be their identity, that participants to complex supply chains consider to be confidential, and that governments classify as secret. That means that data ownership must be entered into the equation for the success of Freebase Parallax and the emerging Semantic Web in general.
Not that Hillis hasn't thought about data ownership. He has. You can see it in an interview conducted by his patent attorney and filed on December 21, 2001 in the provisional USPTO Patent Application 60/343,273:
Danny Hillis: "Here's another idea that's super simple. I've never seen it done. Maybe it's too simple. Let's go back to the terrorist version [of Knowledge Web]. There's a particular problem in the terrorist version that the information is, of course, highly classified .... Different people have some different needs to know about it and so on. What would be nice is if you ... asked for a piece of information. That you [want access to an] annotation that you know exists .... Let's say I've got a summary [of the annotation] that said, 'Osama bin Laden is traveling to Italy.' I'd like to know how do you know that. That's classified. Maybe I really have legitimate reasons for that. So what I'd like to do, is if I follow a link that I know exists to a classified thing, I'd like the same system that does that to automatically help me with the process of getting the clearance to access that material." [emphasis added]
What Hillis was tapping into just a few months after 9/11 is just as relevant to today's information sharing needs.
But bouncing around ideas about how we need data ownership is not the same as developing methods or designs to solve it. What Hillis non-provisionally filed, subsequent to his provisional application, was the Knowledge Web application. Because of its emphasis upon the statistical reliability of annotations, Knowledge web's IP is tailored made for the Semantic Web. But it is not designed for data ownership.The Ownership Web
For the Semantic Web to reach its full potential, it must have access to more than just publicly available data sources. Only with the empowerment of technological data ownership in the hands of people, businesses, and governments will the Semantic Web make contact with a horizon of new, ‘blue ocean’ data.
Conceptually, the Ownership Web would be separate from the Semantic Web, though semantically connected as layer of distributed, enterprise-class web platforms residing in the Cloud.
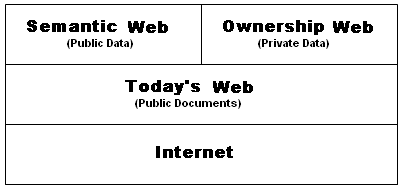
The Ownership Web would contain diverse registries of uniquely identified data elements for the direct authoring, and further registration, of uniquely identified data objects. Using these platforms people, businesses and governments would directly host the authoring, publication, sharing, control and tracking of the movement of their data objects.
The technological construct best suited for the dynamic of networked efficiency, scalability, granularity and trustworthy ownership is the data object in the form of an immutable, granularly identified, ‘informational’ object.
A marketing construct well
suited to relying upon the trustworthiness of immutable, informational
objects would be the 'data bank'.
Data Banking
 Traditional monetary banks meet the expectations of real people and real businesses in the real world.
Traditional monetary banks meet the expectations of real people and real businesses in the real world.
People are comfortable and familiar with monetary banks. That’s a good thing because without people willingly depositing their money into banks, there would be no banking system as we know it. By comparison, we live in a world that is at once awash in on-demand information courtesy of the Internet, and at the same time the Internet is strangely impotent when it comes to information ownership.
In many respects the Internet is like the Wild West because there is no information web similar to our monetary banking system. No similar integrated system exists for precisely and efficiently delivering our medical records to a new physician, or for providing access to a health history of the specific animal slaughtered for that purchased steak. Nothing out there compares with how the banking system facilitates gasoline purchases.
If an analogy to the Wild West is apropos, then it is interesting to reflect upon the history of a bank like Wells Fargo, formed in 1852 in response to the California gold rush. Wells Fargo wasn’t just a monetary bank, it was also an express delivery company of its time for transporting gold, mail and valuables across the Wild West. While we are now accustomed to next morning, overnight delivery between the coasts, Wells Fargo captured the imagination of the nation by connecting San Francisco and the East coast with its Pony Express. As further described in Banking on Granular Information Ownership, today’s Web needs data banks that do for the on-going gold rush on information what Wells Fargo did for the Forty-niners.
Banks meet the expectations of their customers by providing them with security, yes, but also credibility, compensation, control, convenience, integration and verification. It is the dynamic, transactional combination of these that instills in customers the confidence that they continue to own their money even while it is in the hands of a third-party bank.
A data bank must do no less.
Ownership Web: What's Philosophically Needed
 Where exactly is the sweet spot of data ownership?
Where exactly is the sweet spot of data ownership?
In truth, it will probably vary depending upon what kind of data bank we are talking about. Data ownership will be one thing for personal health records, another for product supply chains, and yet another for government classified information. And that's just for starters because there will no doubt be niches within niches, each with their own interpretation of data ownership. But the philosophical essence of the Ownership Web that will cut across all of these data banks will be this:
- That information must be treated either or both as a tangible, commercial product or banked, traceable money.
The trustworthiness of information is crucial. Users will not be drawn to data banks if the information they author, store, publish and access can be modified. That means that even the authors themselves must be proscribed from modifying their information once registered with the data bank. Their information must take on the immutable characteristic of tangible, traceable property. While the Semantic Web is about the statistical reliability of data, the Ownership Web is about the reliability of data, period.
Ownership Web: What's Technologically Needed
What
is technologically required is a flexible, integrated architectural
framework for information object authoring and distribution. One that
easily adjusts to the definition of data ownership as it is variously
defined by the data banks serving each social network, information
supply chain, and product supply chain. Users will interface with one
or more ‘data banks’ employing this architectural framework. But the
lowest common denominator will be the trusted, immutable informational objects
that are authored and, where the definition of data ownership permits,
controllable and traceable by each data owner one-step, two-steps,
three-steps, etc. after the initial share.
 Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems.
Click
on the thumbnail to the left for the key architectural features for
such a data bank. They include a common registry of standardized data
elements, a registry of immutable informational objects, a
tracking/billing database and, of course, a membership database. This is the architecture for what may be called a Common Point Authoring™ system.
Again, where the definition of data ownership permits, users will host
their own 'accounts' within a data bank, and serve as their own
'network administrators'. What is made possible by this architectural
design is a distributed Cloud of systems (i.e., data banks). The
overall implementation would be based upon a massive number of user
interfaces (via API’s, web browsers, etc.) interacting via the Internet
between a large number of data banks overseeing their respective
enterprise-class, object-oriented database systems.
 Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.).
Click on the thumbnail to the right for an example of an informational object
and its contents as authored, registered, distributed and maintained
with data bank services. Each comprises a unique identifier that
designates the informational object, as well as one or more data
elements (including personal identification), each of which
itself is identified by a corresponding unique identifier. The
informational object will also contain other data, such as ontological
formatting data, permissions data, and metadata. The actual data
elements that are associated with a registered (and therefore immutable)
informational object would be typically stored in the Registered Data
Element Database (look back at 124 in the preceding thumbnail). That
is, the actual data elements and are linked via the use of pointers,
which comprise the data element unique identifiers or URIs. Granular portability is built in. For more information see the blogged entry US Patent 6,671,696: Informational object authoring and distribution system (Pardalis Inc.).
The Beginning of the Ownership Web
Common Point Authoring is going live this fall in the form of a data bank for cattle producers in the upper plains. Why the livestock industry? Because well-followed commentators like Dr. Kris Ringwall, Director of the Dickinson Research Extension Center for North Dakota State University, recognize that there are now two distinct products being produced along our nation's complex agricultural supply chains: (1) a traditional product, and (2) an informational product describing the pedigree of the traditional product.
The following excerpt is from a BeefTalk article, Do We Exist Only If Someone Else Knows We Exist?, recently authored by Dr. Ringwall.
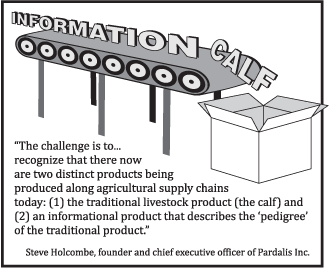 "The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect.
"The
concept of data collection is knocking on the door of the beef
industry, but the concept is not registering. In fact, there actually
is a fairly large disconnect.
This is ironic because most, if not all, beef producers pride themselves on their understanding of the skills needed to master the production of beef. Today, there is another player simply called “data.”
The information associated with individual cattle is critical. Producers need to understand how livestock production is viewed ....
That
distinction is not being made and the ramifications are lost revenue in
the actual value of the calf and lost future opportunity. This is
critical for the future of the beef business ...."
Ownership Web: Where It Will Begin
The Ownership Web will begin along complex product and service supply chains where information must be trustworthy, period. Statistical reliability is not enough. And, as I mentioned above, the Ownership Web will begin this fall along an agricultural supply chain which is among the most challenging of supply
chains when it comes to information ownership. Stay tuned as the planks of the
Ownership Web are nailed into place, one by one.
 Steve Holcombe
Steve Holcombe
Reader Comments